An Easier Approach to Understanding the Synthetic Control Method
Demystify marketing incrementality testing with the synthetic control method (SCM) explained through a thrilling race analogy.
Excerpt
The synthetic control method (SCM) is a commonly used statistical method to create control and treatment groups for experimentation. Geo experimentation, a popular marketing incrementality testing technique utilizes this methodology to create experimentation groupings. In recent years, marketing sciences teams have adopted this approach to experimentation, and the introduction of this probabilistic technique in an otherwise deterministically measured practice has been intimidating to many who aren’t classically trained statisticians. Marketers, analysts, leadership, and even data scientists, fit into this category, all of whom are important in making decisions to impact an organization based on the results from this type of experimentation. I relate to this as someone who had similar struggles and now helps educate others on the topic. A technique I have found useful in understanding this method is by comparing it to a simple 100-meter dash example that will be used to teach you today.
The Build Up
To put together a memorable race, organizers need to begin by selecting athletes who will race each other in a competitive, and fair race. They want sprinters who are almost identical to each other in their running prowess to create an exciting race where the predicted outcome is a toss-up. When we think about how runners are evaluated to ensure this happens, there are a wide variety of variables, qualities, and experiences that are considered during the selection process. Qualities like where they have historically placed in races, the sprinter's height, weight, top speed, and average finish time…the list goes on and on. For the purpose of this article, let us say that on paper, both runners are nearly identical with only slight variations in different categories for each (amount of races, height, etc.).
The Synthetic Control (SCM) starts with the same process. Historical time-series data is segmented by geographical location (e.g. DMA, region, state, city, etc.) and evaluated for a given metric. SCM runs simulations to create control and treatment groups based on the time-series data and geographical groupings, with individually weighted locations within the groupings to create control and treatment groups that are as close in behavior over historical time as possible. The data isn’t perfectly aligned, similar to the sprinters in our example, but close enough in behavior that makes it statistically valid. From the simulations, a model is selected for the test that is based on statistical significance and effect size from the estimations forecasted for the control and treatment for the theoretical duration we simulated.
The Catch
With a fair race on paper, it is time for our experiment (or race). Based on your hypothesis, a change will be made to the treatment group to create an imbalance between the two groups at the time of the start of the race until the finish. Think of it as giving one of the runners a technologically advanced pair of sneakers this is marketed to give an x% boost in their speed. It could give the runner the edge and an unfair advantage, but it isn’t guaranteed, and won’t be determined until the race happens.
The Photo Finish
The runners are off and in only a matter of a few seconds, the race is over! The sprinter with the advanced sneakers has won the race by two seconds. Given the work we did in “The Build Up” section to create the best repeatable race based on statistical standards, we can confidently say that the likely cause of the winning result was the sneakers. Not only that, but we can also say it has proven to shave 2 seconds off the sprinter's race time! The simulations and modeling gave us a reproducible test that allowed us to isolate the impact of the sneaker change from the rest of the variables to validate the causality in the experiment.
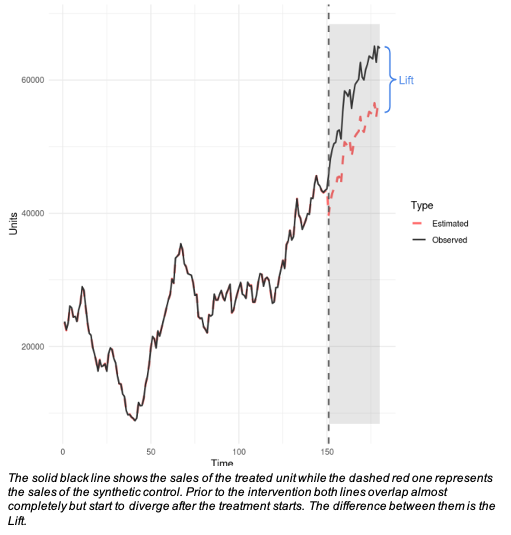
Golden Standard for Causality
I hope that this brief racing analogy helps you understand the concept of synthetic control methods. It might be an intimidating topic to approach at first, but with this new information in mind, remember to think of it as experimenting with a race. With the rise of probabilistic techniques in marketing measurement, all parties involved in Marketing should anticipate more statistical topics like the one I have just discussed. Marketing measurement and decisions will continue to rely on probabilistic techniques like this one, requiring you to understand it to be an effective marketer. Do not sit back and hope someone else can do it for you.
Link to White Paper: Synthetic Control Methods for Comparative Case Studies: Estimating the Effect of California's Tobacco Control Program